Whisper — это система автоматического распознавания речи (ASR) с открыты исходным кодом (Open Source), разработанная OpenAI и выпущенная в открытый доступ в сентябре 2022 года. В отличие от многих других моделей, Whisper обучался на внушительном наборе данных — 680 000 часов многоязычного аудио, собранного из интернета. Благодаря этому Whisper преобразует звук в текст с точностью до 99%.
Кто может им воспользоваться
Редакторы, дикторы и все, кому нужно преобразовывать речь в текст. И это можно использовать совершенно по-разному:
- Если вы провели рабочий звонок в Zoom или Google Meet, вы получите сообщение, которое поможет вам разобраться в контексте, продолжить обсуждение и не упустить ни одной детали.
- Провел собеседование — сразу получил готовый текстовый черновик.
- Проведение презентации на конференции — вы получаете статью с минимальными усилиями.
- Записали лекцию или презентацию проекта — получили готовую текстовую версию.
- Запуск собственного коммерческого сервиса для распознавания речи.
Система обучена на 680 000 часах речевых данных из сети и распознаёт 99 языков.
Для запуска Whisper в Docker, мы будем использовать готовый образ Docker faster-whisper-server. Это совместимый с OpenAI API сервер транскрипции, который использует faster-whisper в качестве бэкенда.
Основные возможности Whisper:
- Настраивается с помощью переменных среды (см.config.py).
- Поддержка графических процессоров.
- Легко развертывается с помощью Docker.
- Совместим с OpenAI API.
- Поддержка потоковой передачи (транскрипция отправляется через SSE по мере расшифровки аудио. Вам не нужно ждать полной расшифровки аудио, чтобы получить его).
- Поддержка транскрипции в реальном времени (аудио отправляется через веб-сокет по мере создания).
- Динамическая загрузка / выгрузка модели. Просто укажите в запросе, какую модель вы хотите использовать, и она будет загружена автоматически. После периода бездействия она будет выгружена.
Смотрите Справочник OpenAI по API для получения дополнительной информации.
Некоторые возможности API:
- Транскрипция аудиофайла через
POST /v1/audio/transcriptionsконечную точку.- В отличие от API OpenAI,
faster-whisper-serverон также поддерживает потоковую расшифровку (и перевод). Это полезно, если вы хотите обрабатывать большие аудиофайлы и получать расшифровку по частям по мере обработки, а не ждать, пока весь файл будет расшифрован. Это работает аналогично сообщениям в чате при общении с большими языковыми моделями.
- В отличие от API OpenAI,
- Перевод аудиофайлов через
POST /v1/audio/translationsконечную точку. - Прямая транскрипция звука через
WS /v1/audio/transcriptionsendpoint.- Алгоритм LocalAgreement2 (статья | оригинальная реализация) используется для оперативной транскрипции.
- Поддерживается только транскрибирование одноканального звука с частотой дискретизации 16000, необработанного, 16-битного, с прямым порядком байтов.
Запуск Faster Whisper в Docker
Для запуска мы будем использовать готовый образ Docker fedirz/faster-whisper-server, так у проекта есть репозиторий на github fedirz/faster-whisper-server.
Использование Docker
docker run --gpus=all --publish 8000:8000 --volume ~/.cache/huggingface:/root/.cache/huggingface fedirz/faster-whisper-server:latest-cuda # или docker run --publish 8000:8000 --volume ~/.cache/huggingface:/root/.cache/huggingface fedirz/faster-whisper-server:latest-cpu
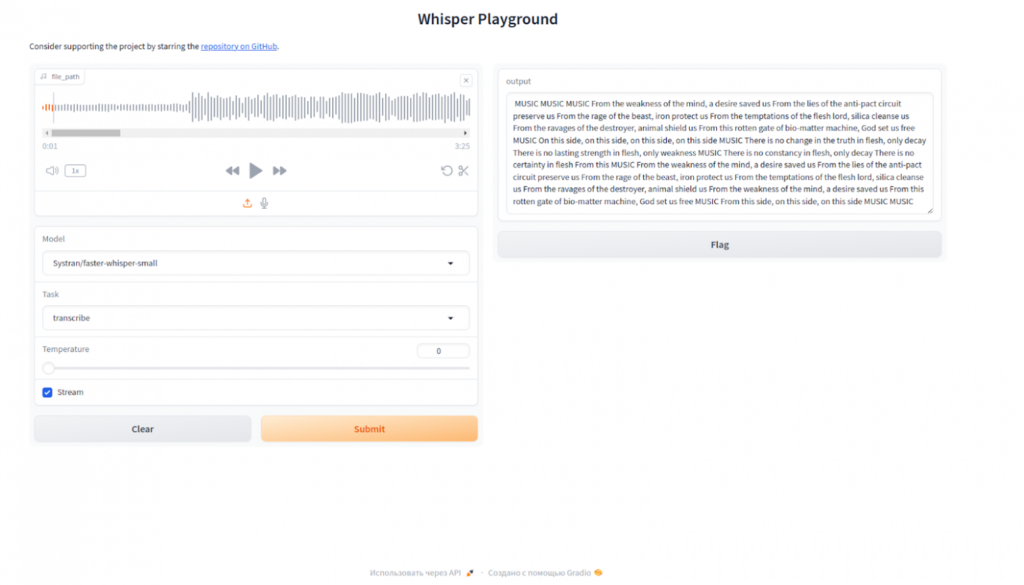
После запуска контейнера интерфейс будет доступен по адресу — IP адрес сервера:8000.
Использование Docker Compose
curl -sO https://raw.githubusercontent.com/fedirz/faster-whisper-server/master/compose.yaml docker compose up --detach faster-whisper-server-cuda # или docker compose up --detach faster-whisper-server-cpu