Теперь Docker — это гораздо больше, чем просто запуск образа контейнера. С помощью Docker Model Runner вы можете запускать LLM локально и взаимодействовать с ними.
Docker Model Runner — это плагин для Docker Desktop, который позволяет вам:
- Извлекать модели с открытым исходным кодом из Docker Hub
- Запускать модели непосредственно из командной строки
- Управлять установками локальной модели
- Взаимодействовать с моделями с помощью подсказок или в режиме чата
- Получать доступ к моделям через конечную точку API, совместимую с OpenAI
В настоящее время Docker Model Runner работает только на Docker Desktop для Mac с чипами Apple Silicon (M1/M2/M3/M4), но поддержка других платформ появится в ближайшее время.
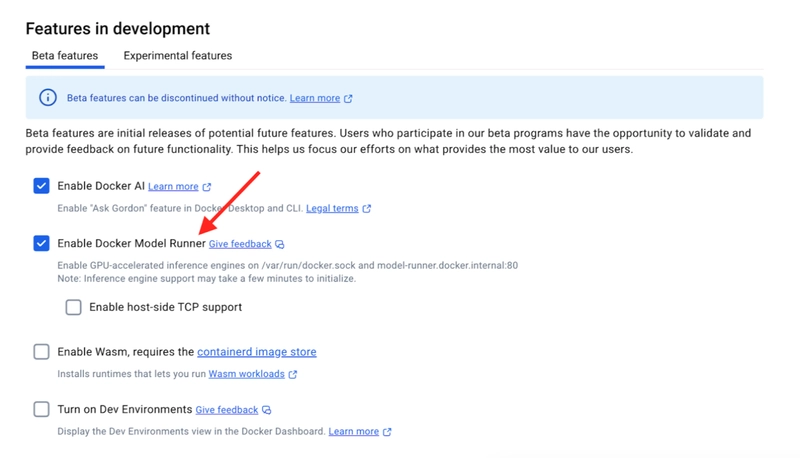
Настройка плагина Docker Model Runner
После установки выполните следующие действия:
- Откройте рабочий стол Docker
- Перейдите в Settings → Features in development (Beta tab) «Настройки» → «Функции в разработке» (вкладка «Бета-версия»).
- Включить «Docker Model Runner»
- Также включите «Enable host-side TCP support» (leave the default port of 12434) «Поддержку TCP на стороне хоста» (оставьте порт по умолчанию 12434)
- Примените и перезапустите Docker Desktop
Запуск LLM ИИ в Docker CLI
После настройки вы можете создать свою первую модель с помощью Docker CLI:
docker model pull ai/gemma3Это загрузит модель Google Gemma 3, которая представляет собой хороший баланс возможностей и использования ресурсов. Вы можетепроверить, какие модели у вас установлены, с помощью:
docker model listЧтобы протестировать ваши настройки, попробуйте запустить модель в интерактивном режиме:
docker model run ai/gemma3Это запускает интерактивный сеанс чата, в котором вы можете напрямую взаимодействовать с моделью прямо в своём терминале:
> What is an interesting fact about Docker?
Docker was originally developed as an internal project at a company called dotCloud,
which was a Platform-as-a-Service company. The technology was later open-sourced in 2013
and became immensely popular, eventually leading to dotCloud pivoting their entire
business to focus on Docker. This pivot transformed the company into Docker, Inc.Использование API (OpenAI)
Одна из замечательных особенностей Model Runner заключается в том, что он реализует конечные точки, совместимые с OpenAI. Мы можем взаимодействовать с API разными способами: внутри работающего контейнера или с хост-машины с помощью TCP или Unix-сокетов.
Мы рассмотрим примеры различных способов, но сначала перечислим доступные конечные точки. Конечные точки останутся неизменными независимо от того, взаимодействуем ли мы с API внутри контейнера или с хоста. Изменится только хост.
# OpenAI endpoints
GET /engines/llama.cpp/v1/models
GET /engines/llama.cpp/v1/models/{namespace}/{name}
POST /engines/llama.cpp/v1/chat/completions
POST /engines/llama.cpp/v1/completions
POST /engines/llama.cpp/v1/embeddings
Note: You can also omit llama.cpp.
Изнутри контейнера
Внутри контейнера мы будем использовать http://model-runner.docker.internal его в качестве базового URL-адреса и сможем обращаться к любой из упомянутых выше конечных точек. Например, мы будем обращаться к /engines/llama.cpp/v1/chat/completions конечной точке для общения в чате.
Мы будем использовать curl. Вы можете заметить, что он использует ту же структуру схемы, что и OpenAI API. Убедитесь, что вы уже загрузили модель, которую пытаетесь использовать.
curl http://model-runner.docker.internal/engines/llama.cpp/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "ai/llama3.2",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Please write 100 words about the docker compose."
}
]
}'
Итак, чтобы проверить, работает ли это внутри запущенного контейнера, я запускаю образ jonlabelle/network-tools в интерактивном режиме, а затем использую приведённую выше команду curl для взаимодействия с API. И это сработало.
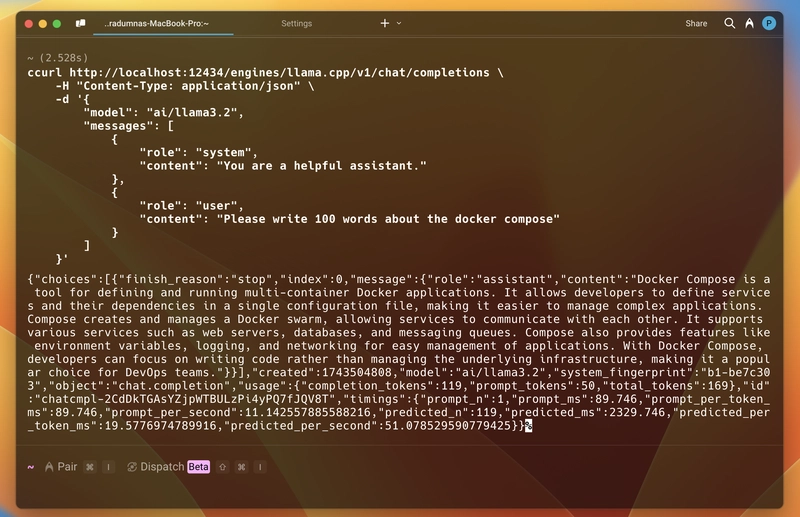
Как видите, ниже приведён ответ, который я получил. Ответ представлен в формате JSON и включает сгенерированное сообщение, использование токена, сведения о модели и время ответа. Как и в стандарте.
Запуск на Хост сервере
Как уже упоминалось ранее, для взаимодействия с API вы должны убедиться, что у вас включен TCP. Вы можете проверить, работает ли он, перейдя по ссылке localhost:12434. Вы увидите сообщение Docker Model Runner. Сервис запущен.
В этом случае в качестве базового URL-адреса будет использоваться http://localhost:12434 и будут использоваться те же конечные точки. То же самое касается команды curl: мы просто заменим базовый URL-адрес, и всё останется по-прежнему.
curl http://localhost:12434/engines/llama.cpp/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "ai/llama3.2",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Please write 100 words about the docker compose."
}
]
}'
Давайте попробуем это, запустив в нашем терминале:
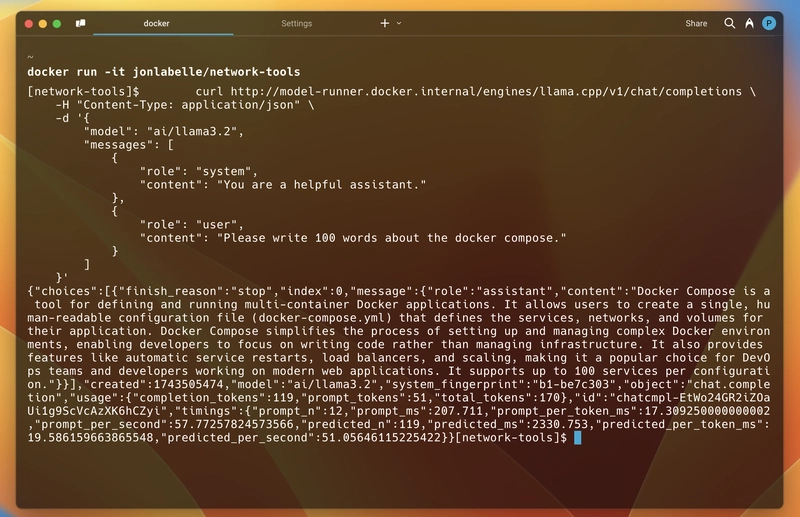
Он вернёт тот же ответ в формате JSON, что и предыдущий, включая сгенерированное сообщение, использование токена, сведения о модели и время ответа.
Благодаря поддержке TCP мы можем взаимодействовать не только с приложениями, запущенными внутри нашего контейнера, но и с любыми другими.
Ссылки